 Do implementation details matter in Deep Reinforcement Learning?
Do implementation details matter in Deep Reinforcement Learning?
A reflection on design, architecture and implementation of DRL algorithms from a software engineering perspective applied to research. Spoiler alert … it does matter!
A quest for answers
While I was finishing an essay on Deep Reinforcement Learning Advantage Actor-Critic method, a part of me felt that some important questions linked to the applied part were unanswered or disregarded.
Which design & architecture should I choose?
Which implementation details are impactful or critical?
Does it even make a difference?
This essay is my journey through that reflection process and the lessons I have learned on the importance of design decisions, architectural decisions and implementation details in Deep Reinforcement Learning (specificaly regarding the class of policy gradient algorithms).
Clarification on ambiguous terminology
- The setting
-
In this essay, with respect to an algorithm implementation, the term
"setting" will refer to any outside element like the following:
- implementation requirement:
method signature, choice of hyperparameter to expose or capacity to run multi-process in parallel…- output requirement:
robustness, wall clock time limitation, minimum return goal…– inputed environment:
observation space dimensionality, discreet vs. continuous action space, episodic vs. infinite horizon…– computing ressources:
available number of cores, RAM capacity… - Architecture (Software)
-
From the wikipedia page on Software
architecture
refers to the fundamental structures of a software system and the discipline of creating such structures and systems. Each structure comprises software elements, relations among them, and properties of both elements and relations.
In the ML field, it often refers to the computation graph structure, data handling and algorithm structure. - Design (Software)
-
There are a lot of different definitions and the line between design and
architectural concern is often not clear. Let’s use the first definition
stated on the
wikipedia page on Software
design
the process by which an agent creates a specification of a software artifact, intended to accomplish goals, using a set of primitive components and subject to constraints.
In the ML field, it often refers to choices made regarding improvement techniques, hyperparameters, algorithm type, math computation… - Implementation details
-
This is a term often a source of confusion in software engineering
I recommend this very good post on the topic of Implementation details by Vladimir Khorikov: What is an implementation detail? . The consensus is the following:everything that should not leak outside a public API is an implementation detail.
So it’s closely linked to the definition and specification of an API but it’s not just code. The meaning feels blurier in the machine learning field as it often gives the impression that it’s usage implicitly means:
everything that is not part of the math formula or the high-level algorithm is an implementation detail.
and also that:those are just implementation details.
Going down the rabbit hole
Making sense of Actor-Critic algorithm scheme definitively ticked my curiosity. Studying the theoretical part was a relatively straight forward process as there is a lot of literature covering the core theory with well-detailed analysis & explanation. On the other hand, studying the applied part has been puzzling. Here’s why.
I took the habit when I study a new algorithm-related subject, to first implement it by myself without any code example. After I’ve done the work, I look at other published code examples or different framework codebases. This way I get an intimate sense of what’s going on under the hood and it makes me appreciate other solutions to problems I have encountered that often are very clever. It also helps me to highlight details I was not understanding or for which I was not giving enough attention. Proceeding this way takes more time, it’s often a reality check and a self-confidence shaker, but in the end, I get a deeper understanding of the studied subject.
So I did exactly that. I started by refactoring my Basic Policy
Gradient implementation toward an Advantage Actor-Critic one. I made
a few attempts with unconvincing results and finally managed to make it
work. I then started to look at other existing implementations. Like it
was the case for the theoretical part, there was also a lot of
available, well-crafted code example & published implementation of
various Actor-Critic class
algorithm
- DeepReinforcementLearningThatMatters on GitHub The accompanying code for the paper "Deep Reinforcement Learning at Matters"
- OpenAI: Spinning Up, by Josh Achiam;
- Ex Google Brain resident Denny Britz GitHub
- Lil’Log GitHub by Lilian Weng, research intern at OpenAI
However, I was surprised to find that most of serious implementations were very different. The high-level ideas were more or less the same, taking into account what flavour of Actor-Critic was the implemented subject, but the implementation details were more often than not very different. To the point where I had to ask myself if I was missing the bigger picture. Was I looking at esthetical choices with no implication, at personal touch taken lightly or was I looking at well considered, deliberate, impactful design & architectural decision?
While going down that rabbit hole, the path became even blurrier when I began to realize that some design implementation related to theory and others related to speed optimization were not having just plus value, they could have a tradeoff on certain settings.
Still, a part of me was seeking for a clear choice like some kind of best practice, design patern or most effective architectural pattern. Which led me to those next questions:
Which design & architecture should I choose?
Which implementation details are impactful or critical?
Does it even make a difference?
Does it even make a difference?
Apparently, it does a great deal as Henderson, P. et al. demonstrated in
their paper Deep reinforcement learning that matters
Regarding implementation details:
One disturbing result they got was on one experiment they conducted on
the performance of a given algorithm across different code base. Their
goal was “to draw attention to the variance due to implementation
details across algorithms”. As an example they compared 3 high quality
implementations of TRPO: OpenAI Baselines
The way I see it, those are all codebase linked to publish papers so they were all implemented by experts and must have been extensively peer reviewed. So I would assume that given the same settings (same hyperparameters, same environment) they would all have similar performances. As you can see, that assumption is wrong.
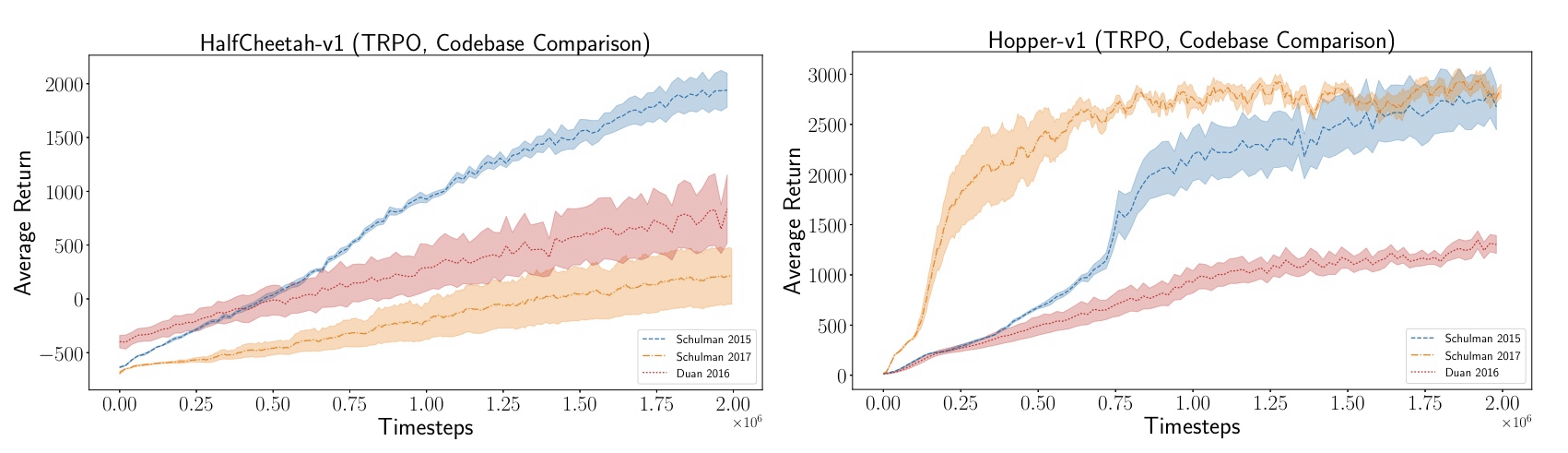
Source: Figure 35 from Deep reinforcement learning that matters
They also did the same experiment with DDPG and got similar results and this is what they found:
... implementation differences which are often not reflected in publications can have dramatic impacts on performance ... This [result] demonstrates the necessity that implementation details be enumerated, codebases packaged with publications ...
This does not answer my question about “Which implementation details are impactful or critical?” however it certainly tells me that SOME implementation details ARE impactful or critical and this is an aspect that deserves a lot more attention.
Regarding the setting:
In another experiment, they examined the impact an environment choice
could have on policy gradient family algorithm performances. They made a
comparison using 4 different environments with 4 different algorithms.
Maybe I’m naive, but when I read on an algorithm, I usually get the impression that it outperforms all benchmark across the board. Nevertheless, their result showed that:
no single algorithm can perform consistently better in all environments.
To me, that sounds like an important detail. If putting an algorithm in a given environment has such a huge impact on its performance, would it not be wise to take it into consideration before planning the implementation as it could clearly affect the outcome. Otherwise it’s like expecting a Formula One to perform well in the desert during a Paris-Dakar race on the basis that it holds a top speed record of 400 km/h. They concluded that:
In continuous control tasks, often the environments have random stochasticity, shortened trajectories, or different dynamic properties ... as a result of these differences, algorithm performance can vary across environments ...
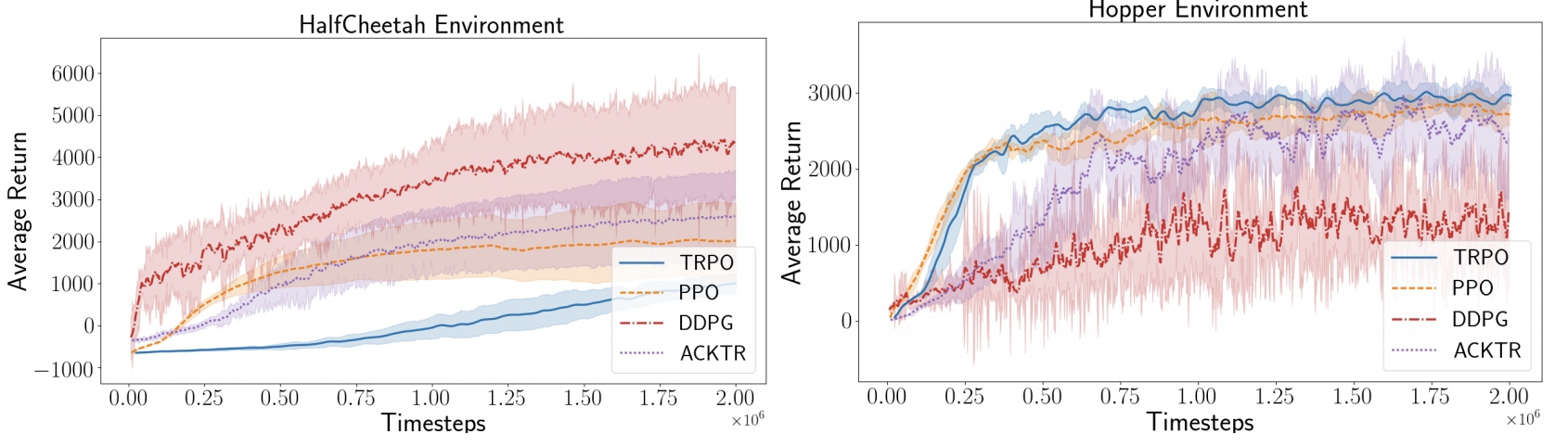
Source: Figure 26 from Deep reinforcement learning that matters
Regarding design & architecture:
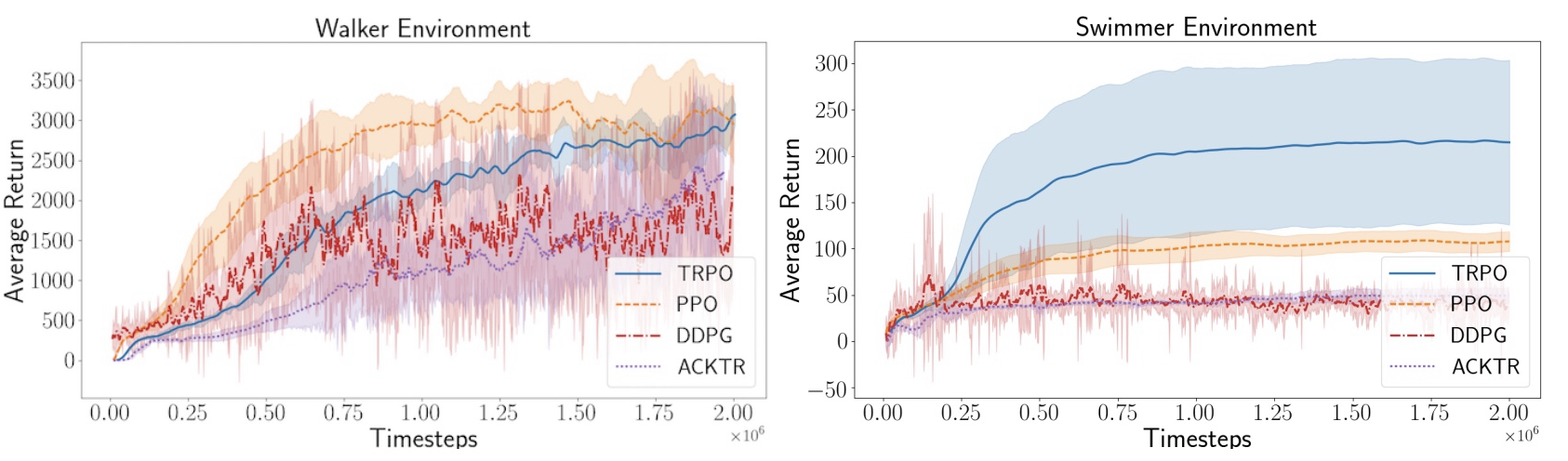
They have also shown how policy gradient class algorithms can be affected by choices of network structures, activation functions and reward scale. Here are a few examples:
Figure 2 shows how significantly performance can be affected by simple changes to the policy or value network

Source: Figure 2 from Deep reinforcement learning that matters
Our results show that the value network structure can have a significant effect on the performance of ACKTR algorithms.
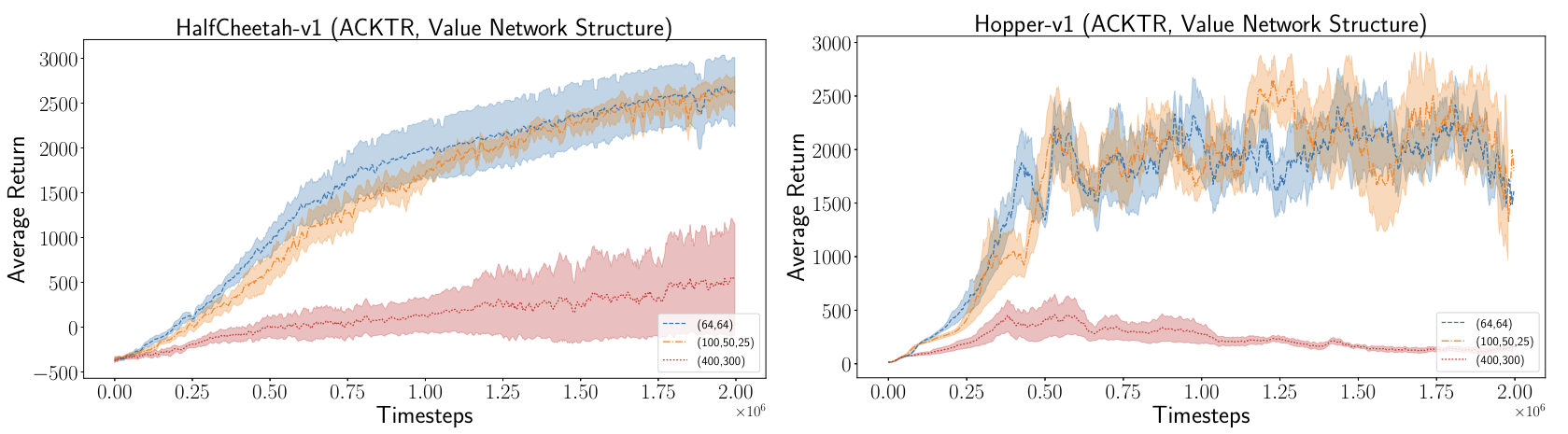
Source: Figure 11 from Deep reinforcement learning that matters
They make the following conclusions regarding network structure and activation function:
The effects are not consistent across algorithms or environments. This inconsistency demonstrates how interconnected network architecture is to algorithm methodology.
It’s not a surprise that hyperparameter has an effect on the performance. To me, the key takeaway is that policy gradient class algorithm can be highly sensitive to small changes, enough to make it fall or fly if not considered properly.
Ok it does matter! … What now?
Like I said earlier, the goal of their paper was to highlight problems regarding reproducibility in DRL publication. As a by-product, they clearly establish that DRL algorithm can be very sensitive to change like environment choice or network architecture. I think it also showed that the applied part of DRL, whether it’s about implementation details or design & architectural decisions, play a key role and is detrimental to a DRL project success just as much as the mathematic and the theory on top of which they are built. By the way, I really liked that part of their closing thought, which reads as follows:
Maybe new methods should be answering the question: in what settings would this work be useful?
Which implementation details are impactful or critical?
We have established previously that implementation details could be impactful with regards to the performance of an algorithm eg.: how fast it converges to an optimal solution or if it converges at all.
Could it be impactful else where? Like wall clock speed for example or memory management. Of course it could, any book on data structure or algorithm analysis support that claim. On the other end, there is this famous say in the computer science community :
Early optimization is a sin.
Does it apply to the ML/RL field? Anyone that has been waiting for an experiment to conclude after a few strikes will say that waiting for result is playing with their mind and that speed matters a lot to them at the moment. Aside from mental health, the reality is that the faster you can iterate between experiments, the faster you get feedback from your decisions, the faster you can make adjustments towards your goals. So optimizing for speed sooner than later is impactful indeed in ML/RL. It’s all about choosing what is a good optimization investment.
We need to train two neural network:
-
the actor network
\widehat{\pi}_{\theta} (the one reponsible for making acting decision in the environment) -
the critic network
\widehat{V}_\phi^\pi (the one responsible for evaluating if\widehat{\pi}_\theta is doing a good job)
The gradient of the Actor-Critic objective goes like this
Training the critic network
-
the
i^e input\:\: \mathbf{x}^{_{(i)}} \, := \, \mathbf{s}_{t} \:\: -
and the bootstrap target
\:\: y^{_{(i)}} \: := \: r_{t+1}^{_{(i)}} \, + \, \widehat{V}_\phi^\pi(\mathbf{s}_{t+1}^{_{(i)}})
So we now need to look for 2 types of implementation details:
- those related to algorithm performance
- and those related to wall clock speed.
That’s when things get trickier. Take for example the value estimate computation of the critic
Does it even make a difference?
Casse 1 - timestep level : Choosing to do this operation at each timestep instead of doing it over
a batch might make no difference on a CartPole-v1 Gym
environment
since you only need to store in RAM at each timestep a 4-digit
observation and that trajectory length is capped at $200$ steps so you
end up with relatively small batches size. Even if that design choice
completely fails to leverage the power of matrix computation framework,
considering the setting, computing
Casse 2 - batch level : On the other hand, using the same design in an environment with very
high dimensional observation space like the PySc2
Starcraft environment
Casse 3 - trajectory level : Now let’s consider trajectory length. As an example, a 30-minute PySc2
Starcraft game is
What I want to show with this example is that some implementation details might have no effect in some settings but can be a game changer in others.
This means that it’s a setting sensitive issue and the real question we need to ask ourselves is:
How do we recognize when an implementation detail
becomes impactful or critical?
Asking the right questions
From my understanding, there is no cookbook defining the recipe of a one best design & architecture that will outperform all the other ones in every setting, maybe there was at one point, but not anymore.
As a matter of fact, it was well establish since de 90’s that Temporal-Diference RL method were superior to
Monte-Carlo RL method. Never the less, it was recently highlithed by Amiranashvili et al.
(2018)
We find that while TD is at an advantage in tasks with simple perception, long planning horizons, or terminal rewards, MC training is more robust to noisy rewards, effective for training perception systems from raw sensory inputs, and surprisingly successful in dealing with sparse and delayed rewards.
We also saw earlier that there was no clear winner amongst policy gradient class algorithms
We are now left with the following unanswered questions:
Why choose a design & architecture over another?
How do I recognize when an implementation detail becomes impactful
or critical?
I don’t think there is a single answer to those questions and gaining experience at implementing DRL algorithm might probably help, but it’s also clear that none of those questions can be answered without doing a proper assessment of the settings. I think that design & architectural decisions need to be well thought out, planned prior to development and based on multiple considerations like the following:
- output requirement (eg. robustness, generalization performance, learning speed, ...)
- environment to tackle (eg. action space dimensionality, observation type ...)
- resource available to do it (eg. computation power, data storage ...)
One thing for sure, those decisions cannot be
a “flavour of the month”-based decision.
I will argue that learning to recognize when implementation details becomes important or critical is a valuable skill that needs to be developed.
Closing thoughts
In retrospect, I have the feeling that the many practical aspects of DRL are maybe sometimes undervalued in the literature at the moment but my observation led me to conclude that it probably plays a greater role in the success or failure of a DRL project and it’s a must study.